猿人学18题链接
https://match.yuanrenxue.com/match/18
1.初步分析,找到加密点
要求爬取后几个数据
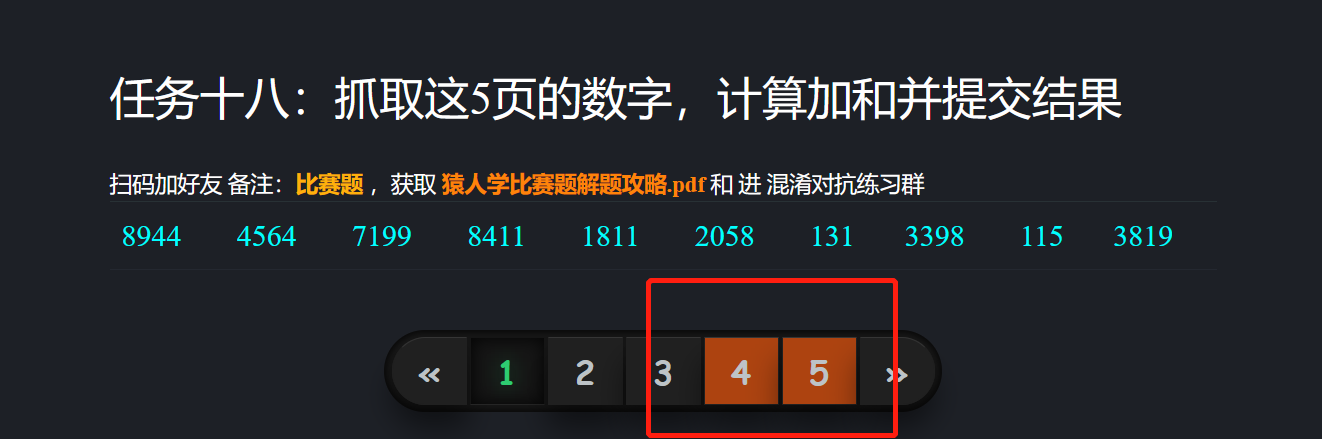
当点击4,5页面时会出现
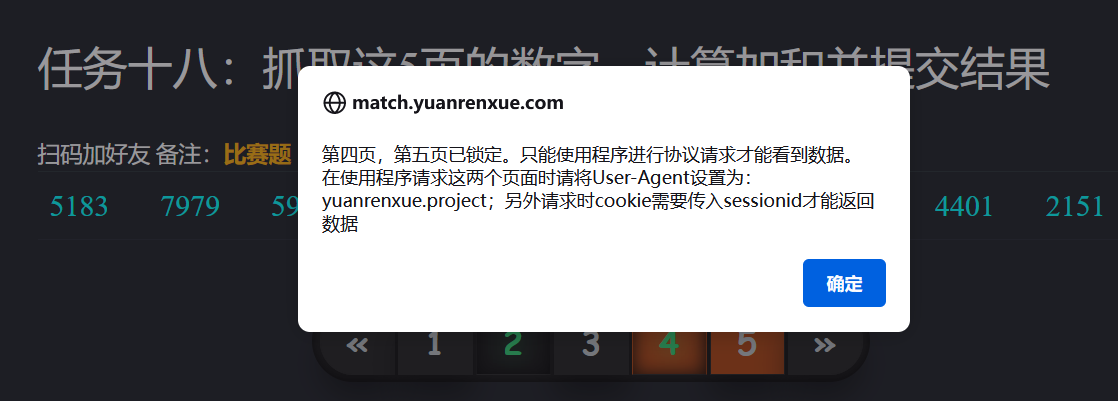
此时抓包改ua
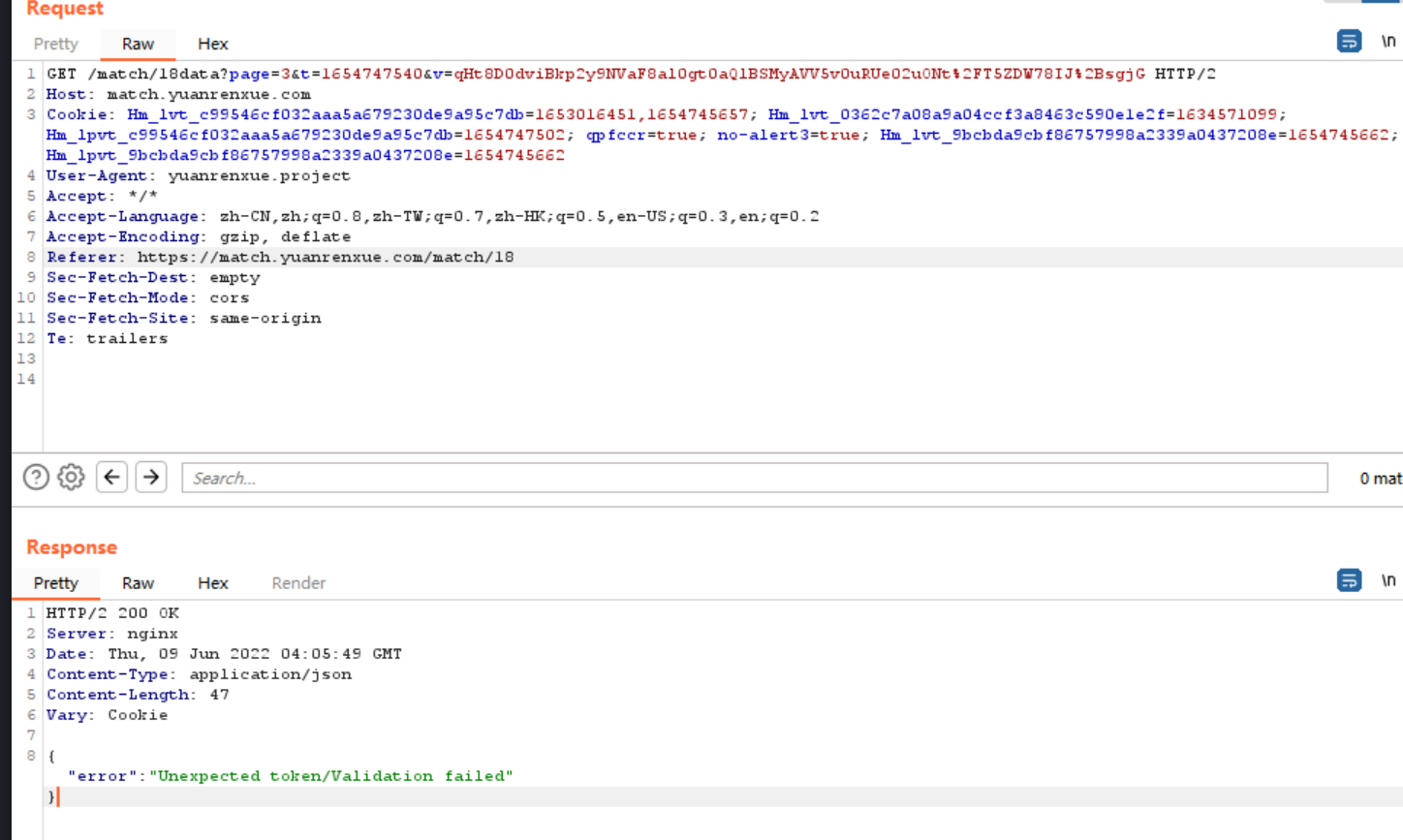
会显示如上界面,也就是必须要破解v参数,否则会触发风控系统
那么对ajax请求进行栈跟踪,找到加密处
进入getdata,向前面的代码打上断点#也就是xml.send()的前面
因为一般来说加密过程在发送数据包的前面

由上图可以看出请求的page只有1,并没有v=后面的加密数据,所以推测加密算法在xml.open()后面,继续步进

可以看到这是混淆代码,所以应该就来到了加密处(firefox不知道为什么不能很好的格式化输出,只好用chrome了)
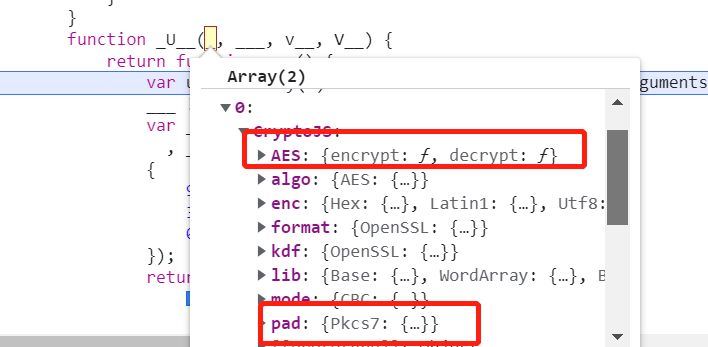
观察传入的四个参数,可以找到有一个是上图所示,不难看出是AES加密,且填充方式是pkcs7
那么就可以通过这点进行hook,观察加密参数是什么
保持断点不动,切到console
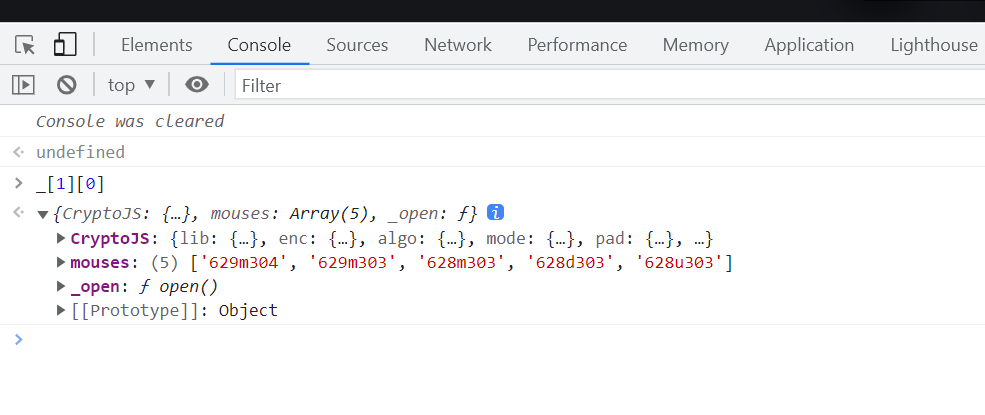
当输入_[1][0]时可以看到加密相关的参数,我们需要的就是覆盖掉加密函数,这样就能保证每次他进行加密的时候可以知道加密了哪些参数2.hook AES加密,分析加密数据
继续上一步,到console,当我想定义变量的时候,出现以下错误
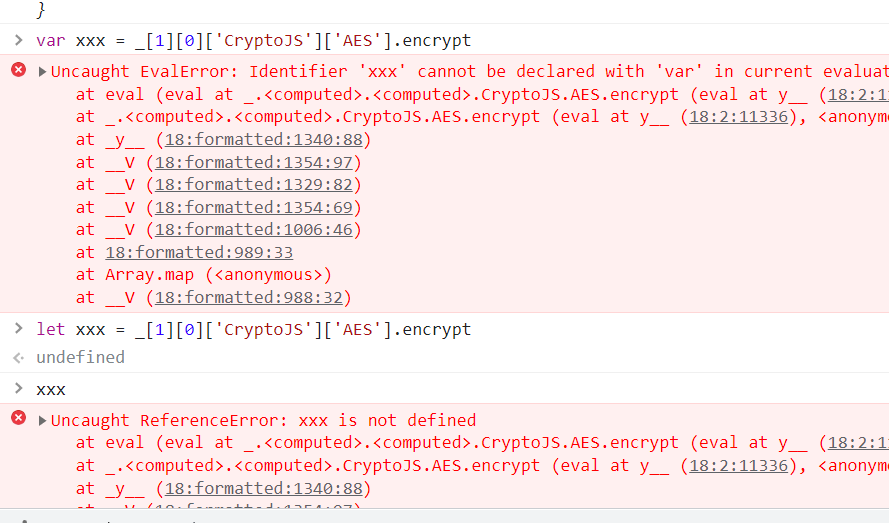
不知道是什么原因,思考良久以后发现只要在进入混淆代码之前就把变量定义出来就行,如下图
在这时候切到console界面,然后定义变量,到时候就用这个变量
回到调试器,继续步进,回到混淆代码处1
2
3
4
5
6
7
8org_encrypto = _[1][0]['CryptoJS']['AES'].encrypt;
_[1][0]['CryptoJS']['AES'].encrypt = function(a,b,c,d,e){
debugger;
var result = org_encrypto(a,b,c,d,e);
console.log(org_encrypto.toString());
return result;
};
然后在控制台输入以上代码,进行hook操作
接下来直接继续脚本执行不用f11什么的步进
当他进行加密操作的时候,会自动跳转到刚刚覆盖的函数encrypt
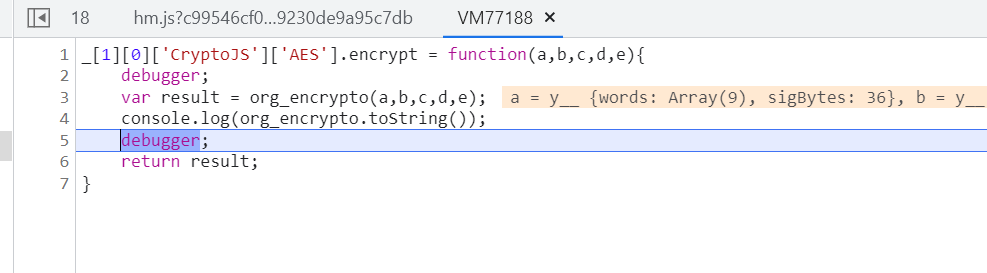
这时候就可以看到具体加密了什么参数了,到控制台输出一下

1
2
3_[1][0]['CryptoJS'].enc.Utf8.stringify(a) //text
_[1][0]['CryptoJS'].enc.Utf8.stringify(b) //key
_[1][0]['CryptoJS'].enc.Utf8.stringify(c.iv) //iv那么接下来就是分析这些参数具体是怎么生成的了
在调用栈里面回到上一个调用函数
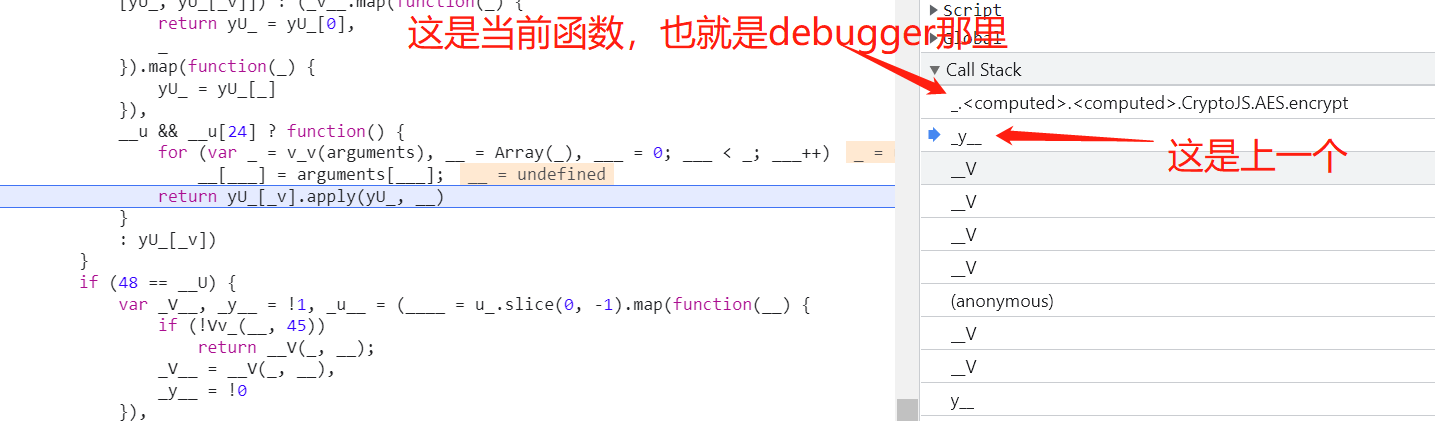
那么在此添加日志断点,可以输出所有经过此函数的变量

这时候把其它断点都去掉,页面刷新一下把hook的函数也去掉,只留下日志断点

可以看到当鼠标移动的时候会在控制台输出以上信息,这时候点击第二页(第三页也行都一样)
可以看到控制台输出了很多其它信息,往上翻找,找到第一次变化的地方
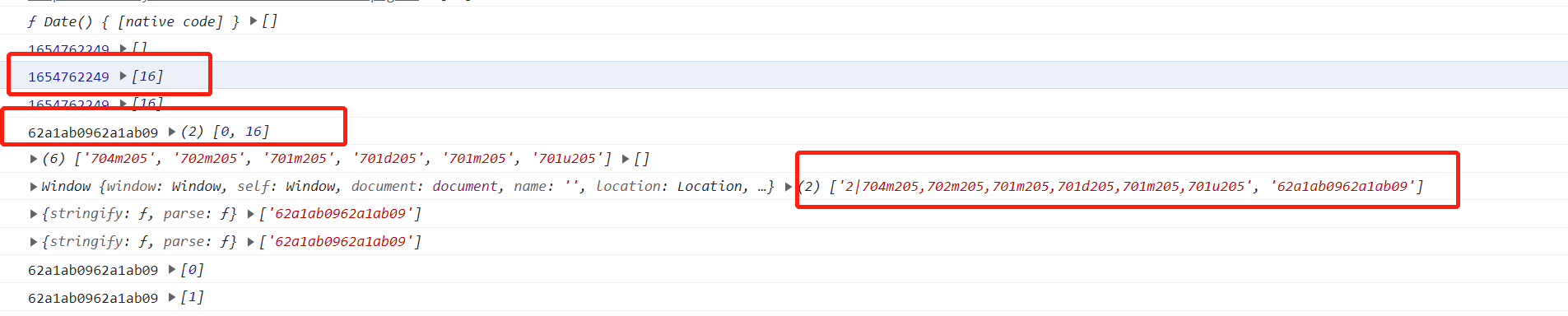
1654762249第一个数据,很明显是时间戳
后面跟了一个16,猜测是把时间戳进行16进制转换
用计算器算了一下确实如此,结果为62a1ab09,然后再把结果进行拼接,变为了62a1ab0962a1ab09
而另一个数据就是把6个鼠标移动位置进行了拼接,然后前面2|就是当前页码,最后变为2|704m205,702m205,701m205,701d205,701m205,701u205
那么最后结果就一目了然了,text就是鼠标移动加页面的拼接,另外两个就是iv和key,在这里iv=key
往下翻找到加密后的数据(当然在network那栏也可以找到)也就是v=

用上面的数据进行加密,看看结果是否符合
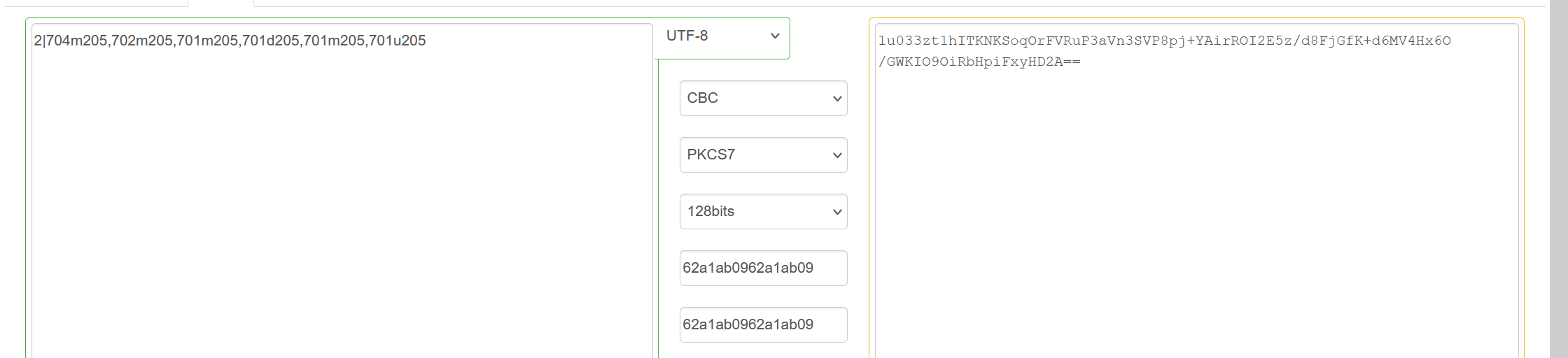
显然是符合的,有些不一样是因为被url编码了,那么具体加密也了解了,现在开始写python脚本了3.脚本实现
首先需要获取当前时间戳,并将其转换为16进制,再进行拼接
1
2AESKEY = hex(int(time.time())).strip('0x')+hex(int(time.time())).strip('0x')
AESIV = AESKEY然后是对鼠标位置的拼接,这里直接将上面的鼠标键位复制下来,后与第四页进行拼接
text = '4|704m205,702m205,701m205,701d205,701m205,701u205'
然后在用AES加密1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56from Crypto.Cipher import AES
import base64
import time
AESKEY = hex(int(time.time())).strip('0x')+hex(int(time.time())).strip('0x')
AESIV = AESKEY
class AESTool:
def __init__(self):
self.key = AESKEY.encode('utf-8')
self.iv = AESIV.encode('utf-8')
def pkcs7padding(self, text):
"""
明文使用PKCS7填充
"""
bs = 16
length = len(text)
bytes_length = len(text.encode('utf-8'))
padding_size = length if (bytes_length == length) else bytes_length
padding = bs - padding_size % bs
padding_text = chr(padding) * padding
self.coding = chr(padding)
return text + padding_text
def aes_encrypt(self, content):
"""
AES加密
"""
cipher = AES.new(self.key, AES.MODE_CBC, self.iv)
# 处理明文
content_padding = self.pkcs7padding(content)
# 加密
encrypt_bytes = cipher.encrypt(content_padding.encode('utf-8'))
# 重新编码
result = str(base64.b64encode(encrypt_bytes), encoding='utf-8')
return result
def aes_decrypt(self, content):
"""
AES解密
"""
cipher = AES.new(self.key, AES.MODE_CBC, self.iv)
content = base64.b64decode(content)
text = cipher.decrypt(content).decode('utf-8')
return self.pkcs7padding(text)
text = '2|704m205,702m205,701m205,701d205,701m205,701u205'
v = aes_tool.aes_encrypt(text)
url = 'https://match.yuanrenxue.com/match/18data?page=2&t={}&v={}'
data = {
'User-Agent':'yuanrenxue.project'
}
r = requests.get(url.format(timestamp,v),data=data)
print(r.text)由于我没有帐号,所以没有session_id,所以无法获取后两页,但是前两页是可以用python获取的,所以逻辑应该是没有问题的
