前言
写这篇文章就是来简单理解一下他反序列化的原理,内核实现
在调试fastjson的时候可能会遇到Source code does not match the bytecode的情况(IJ),我的解决方案是下载源码去阅读
fastjson基本用法
文章的fastjson版本1
2
3
4
5
6
7<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.23</version>
</dependency>
</dependencies>
fastjson主要是用来序列化与反序列化JavaBean
下面是一个简单的JavaBean对象1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public class Student {
private String name;
private int age;
public Student(){
System.out.println("Student无参构造器");
}
public Student() {
this.name = name;
this.age = age;
System.out.println("Student构造函数");
}
public String getName() {
System.out.println("getName");
return name;
}
public int getAge() {
System.out.println("getAge");
return age;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public void setAge(int age) {
System.out.println("setAge");
this.age = age;
}
}
序列化
下面将用fastjson来序列化上面的对象,将他们转换为json
新建一个文件StudentSer.java1
2
3
4
5
6
7
8
9
10import com.alibaba.fastjson.*;
import com.alibaba.fastjson.parser.Feature;
import com.alibaba.fastjson.serializer.SerializerFeature;
public class StudentSer {
public static void main(String[] args) {
String serJson = JSON.toJSONString(new Student("kaikaix",20));
System.out.println(serJson);
}
}
打印了getAge和getName,说明在序列化的时候会对getXxxx进行调用
当然不止toJSONString,还有toJSONBytes,具体可以看JSON.class类中的成员方法
反序列化
接下来就是反序列化了,这里的反序列化类似php,并不是读取字节文件,而是读取json格式的字符串1
2
3
4
5
6
7
8
9
10
11
12
13import com.alibaba.fastjson.*;
import com.alibaba.fastjson.parser.Feature;
import com.alibaba.fastjson.serializer.SerializerFeature;
public class StudentSer {
public static void main(String[] args) {
String serJson = JSON.toJSONString(new Student("kaikaix",20));
System.out.println(serJson);
System.out.printf("Parse had done => %s\n",JSON.parse(serJson).getClass());
System.out.printf("parseObject has done => %s\n",JSON.parseObject(serJson).getClass());
System.out.printf("parseObject(Student.class) has done => %s\n",JSON.parseObject(serJson,Student.class).getClass());
}
}
在这里进行了三次反序列化
主要就是parse和parseObject
但是观察parseObject的源码,其实也是对parse的一次封装,核心还是调用了parse,主要区别就是对parse后返回的obj调用了一次toJSON,调用toJSON就会调用类中所有get,set方法1
2
3
4public static JSONObject parseObject(String text) {
Object obj = parse(text);
return obj instanceof JSONObject ? (JSONObject)obj : (JSONObject)toJSON(obj);
}
我们注意到,只有最后一次反序列化的时候调用了setXxx方法,因为最后一次传递了一个Student.class给他,fastjson才能知道这段String最后到底应该反序列化为哪个对象
而且反序列化的时候调用的构造函数是无参构造器,所以fastjson反序列化的JavaBean必须有无参构造器,否则就会报错
@type
如果每次都需要传递具体是哪个类的,就会显得这个反序列化很笨重,所以开发者给定了一个@type的键,可以在json字符串里面指定具体要反序列化为哪个对象serJson = "{\"@type\":\"Student\",\"age\":12,\"name\":\"Sam\"}";
如果是将这样的json字符串进行反序列化,那么上面的三种反序列化方式也都可以正确反序列化
所以这个点也是后续漏洞的核心关键
反序列化源码分析
No1 DefaultJSONParser
首先会进入这里,new了一个DefaultJSONParser对象
跟进去会首先判断第一个字符是什么,如果是“{”,就会将token设置为12,如果是“[”,就会设置14,如果都不是就会进入nextToken,主要作用就是看下一个字符是什么,如果碰到了“{”就将token设置为121
2
3
4
5//部分代码
case '[':
this.next();
this.token = 14;
return;
当然还有其它情况,比如碰到空格之类的,就会继续跳到下一个字符,直到碰到像“{”这样的字符,有时绕waf可能就会用到这些特性,比如在json前面填充垃圾字符serJson = " {\"@type\":\"Student\",\"age\":12,\"name\":\"Sam\"}";
剩下的读者可以自行分析
小插曲
这里我将{}改成了[],然后进行了反序列化serJson = "[\"@type\":\"Student\",\"age\":12,\"name\":\"Sam\"]";
但是报错了,继续fuzz,试了一下{开头,]结尾
虽然最后报错了,但是前面确实可以反序列化,说不定这种就可以绕一下waf

注意上面的操作都是在json字符串之前的,也就是在“{”前面的一些检查,接下来就进入{}里面了
No2 parseObject()->skipWhitespace()
走完DefaultJSONParser的初始化,就进入到parser.parse()
因为之前是{,所以设置的token为12,所以就会进入这个case
由于字节的原因,我不能在这下断点,所以我直接将断点打到parseObject里面
直接跳到这个循环处
第一个函数根据英文意思skipWhitespace,可以大概猜出是跳过空白字符串1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public final void skipWhitespace() {
while(true) {
while(true) {
if (this.ch <= '/') {
if (this.ch == ' ' || this.ch == '\r' || this.ch == '\n' || this.ch == '\t' || this.ch == '\f' || this.ch == '\b') {
this.next();
continue;
}
if (this.ch == '/') {
this.skipComment();
continue;
}
}
return;
}
}
}
可以看到具体实现,不仅可以跳过空格,换行之类的,还可以跳过注释(skipComment)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29protected void skipComment() {
this.next();
if (this.ch != '/') {
if (this.ch == '*') {
this.next();
while(this.ch != 26) {
if (this.ch == '*') {
this.next();
if (this.ch == '/') {
this.next();
return;
}
} else {
this.next();
}
}
} else {
throw new JSONException("invalid comment");
}
} else {
do {
this.next();
} while(this.ch != '\n');
this.next();
}
}
那么就是/*xxxx*/1
2
3
4{"@type":"Student"}
{ "@type":"Student"}
{/**/"@type":"Student"}
{/*abcdef*/"@type":"Student"}
那么这四种其实效果相同,都可以达到反序列化的目的
No3 parseObject()->AllowArbitraryCommas
在走完上面的判断以后,接下来就是
同样,根据字面意思和代码,大概推断就是判断有没有逗号,如果有就跳过
也就是{,,,,"@type":"Student"},也是可以进行正常反序列化的
No4 parseObject()->scanSymbol()
继续往下走
因为走完前面的一系列操作,那么当前的字符就是@type之前的双引号了
这里的scanSymbol很重要,主要就是扫描到下一个双引号出现之前的字符串,在这就是@type
其中有几段比较重要的特性,我这截取了部分代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22if (chLocal == '\\') {
chLocal = this.next();
switch(chLocal)
{
case 'u':
char c1 = this.next();
char c2 = this.next();
char c3 = this.next();
char c4 = this.next();
int val = Integer.parseInt(new String(new char[]{c1, c2, c3, c4}), 16);
hash = 31 * hash + val;
this.putChar((char)val);
break;
case 'x':
char x1 = this.ch = this.next();
char x2 = this.ch = this.next();
int x_val = digits[x1] * 16 + digits[x2];
char x_char = (char)x_val;
hash = 31 * hash + x_char;
this.putChar(x_char);
}
}
什么意思呢,就是当遇见斜杠,那么就看斜杠后面第一个字母是什么
如果是u那就读取u后面4位,当作unicode解码
同理如果是x就当作十六进制解码1
2
3
4
5{"@type":"Student"}
{"\u0040\u0074\u0079\u0070\u0065":"Student"}
{"\u0040\u0074\u0079pe":"Student"}
{"\x40\x74\x79\x70\x65":"Student"}
{"\x40\x74\x79pe":"Student"}
这上面5个json是等价的,都可以正常进行反序列化
No5 parseObject()->TypeUtils.loadClass()
提取完了@type这个键的字符串以后,就要解析键值了,在这里就是Student
可以看到同样用到了scanSymbol,也就是说我们的类名也可以用十六进制和unicode去编码{"\x40\x74\x79pe":"\u0053\u0074\u0075dent"}
接着就进入到了loadClass了,动态加载类
首先会在mappings中去找是否存在这些类,如果不存在就跳到1
2
3
4
5if (classLoader != null) {
clazz = classLoader.loadClass(className);
mappings.put(className, clazz);
return clazz;
}
去动态加载类,并且将类和类名添加到mappings中,然后返回此类,这里的mappings其实是一个缓存,一般是java的原生类,关于动态加载类到底知识可以自己百度搜索一下,这里不细说
小插曲
这里我注意到了中间两个if语句
第一个:如果第一个字符是“[”,那么就将他去掉,在进行loadClass
第二个:如果第一个字符是“L”,且结尾是“;”,那么也是去掉以后调用loadClass
这里我fuzz了一下{"@type":"[Student"}
中括号加在最前面会报错,不知道为什么,但是根据他的报错信息,我最后整理了一个新的可以利用的,在下一篇我会说一下我是如何找出这样的payload的{"@type":"[Student"[{,"age":12,"name":"kaikaix"}{"@type":"LStudent;"}{"@type":"LLStudent;;"}
这样就不会报错,可以继续接下来的操作,调用无参构造和set方法
No6 parseObject()->getDeserializer()
接下来到了
我们进入到getDeserializer中,中间会到了一个denyList的一个循环
这里前面的replace是将“$”替换为“.”
如果A类中有个内部类B
在编译的时候会生成A.class和A$B.class
那么这一段代码就是用来检查你的类名是否在黑名单中,但是在这个版本的fastjson,黑名单只有两个Thread类
No7 parseObject()->getDeserializer()->createJavaBeanDeserializer()
过了黑名单以后,就会与一些fastjson支持的类进行匹配,如果匹配到了就会返回相应的Deserializer
如果匹配不到就到下图代码中的地方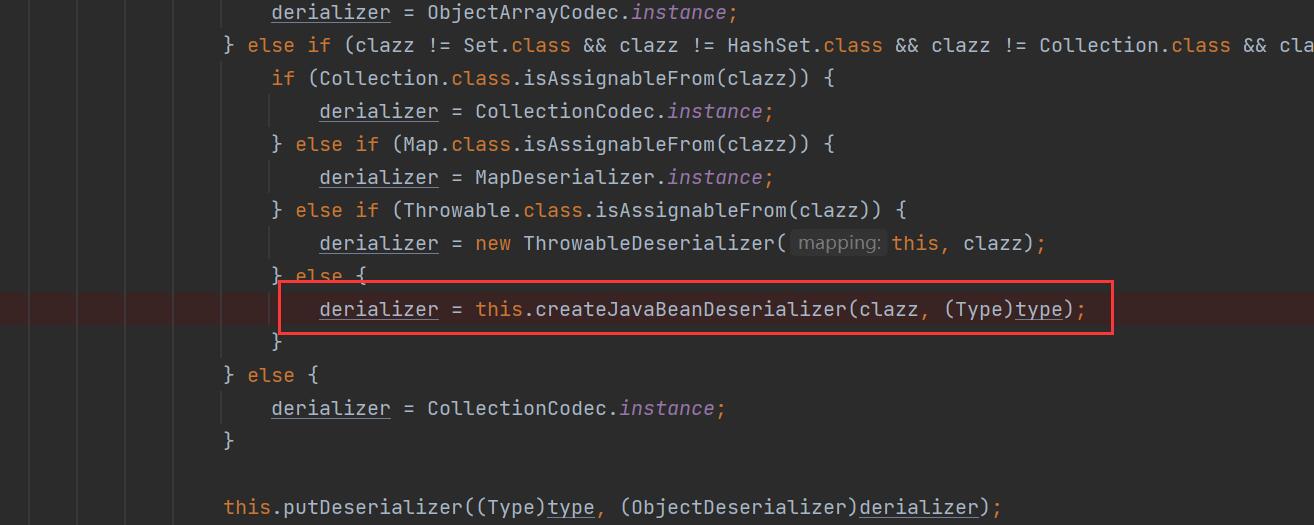
进入到这个函数中会先获取一下clazz的父类,然后就到了这里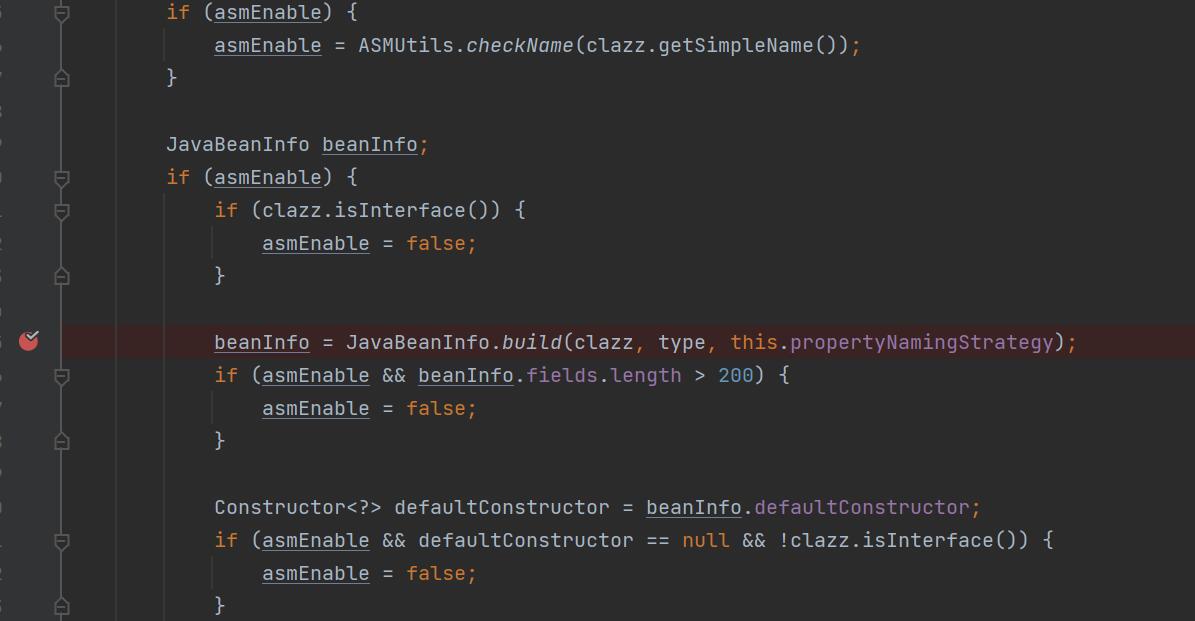
主要就是通过获取构造函数和一些成员方法构建了一个JavaBeanInfo类,并返回
这里需要提的是,他在内部会判断一个成员方法是否是setXxx方法或getXxx方法,如果符合一些条件就会添加入fieldList这个数组中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45//set的
if (methodName.length() >= 4 &&
!Modifier.isStatic(method.getModifiers()) &&
(method.getReturnType().equals(Void.TYPE) ||
method.getReturnType().equals(method.getDeclaringClass()))){
if (methodName.startsWith("set")) {
add(fieldList, new FieldInfo(
propertyName,
method,
field,
clazz,
type,
ordinal,
serialzeFeatures,
parserFeatures,
annotation,
fieldAnnotation,
(String)null
)
);
}
}
//get的
if (methodName.length() >= 4 &&
!Modifier.isStatic(method.getModifiers()) &&
methodName.startsWith("get") &&
Character.isUpperCase(methodName.charAt(3)) &&
method.getParameterTypes().length == 0 &&
(Collection.class.isAssignableFrom(method.getReturnType()) ||
Map.class.isAssignableFrom(method.getReturnType()) ||
AtomicBoolean.class == method.getReturnType() ||
AtomicInteger.class == method.getReturnType() ||
AtomicLong.class == method.getReturnType())){
add(fieldList, new FieldInfo(
propertyName,
method,
(Field)null,
clazz,
type, 0, 0, 0,
annotation,
(JSONField)null,
(String)null)
);
}
从上面的代码可以看出,如果要把set方法添加进入fieldList,那么此方法需要满足的几个点
- 返回值为void类型或者返回值的类型是当前类
- 不能是静态方法
- 开头是set
我这里用下面两块代码来解释一下第一点1
2
3
4
5
6
7
8
9public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public Student setName(String name) {
System.out.println("setName");
this.name = name;
return this;
}
get的满足条件
- Method不是静态的
- Method无参数
- Method的返回类型要继承自上面所写的类
接下来解释一下FieldInfo的几个重要参数
- propertyName,简而言之就是getXxx或setXxx的Xxx,也就是相应方法的变量名称,是一个字符串类型
- method,就是一个Method类,是getXxx或setXxx的反射
这个fieldList在后面调用方法的时候有重要作用
当把所有相应的方法加到fieldList中后,就到了这个函数的最后一步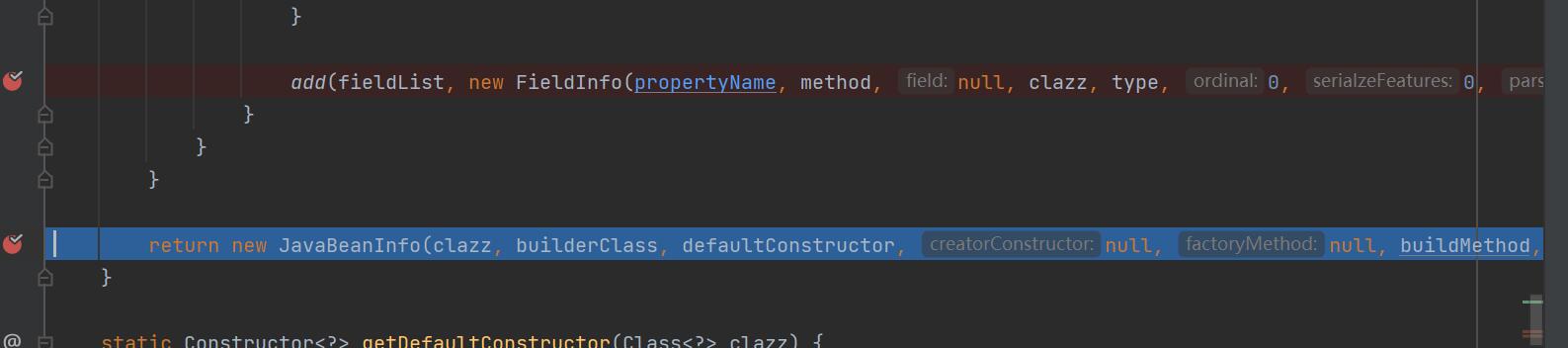
return new JavaBeanInfo(clazz, builderClass, defaultConstructor, null, null, buildMethod, jsonType, fieldList);
会把fieldList和该class类的反射封装到JavaBeanInfo里面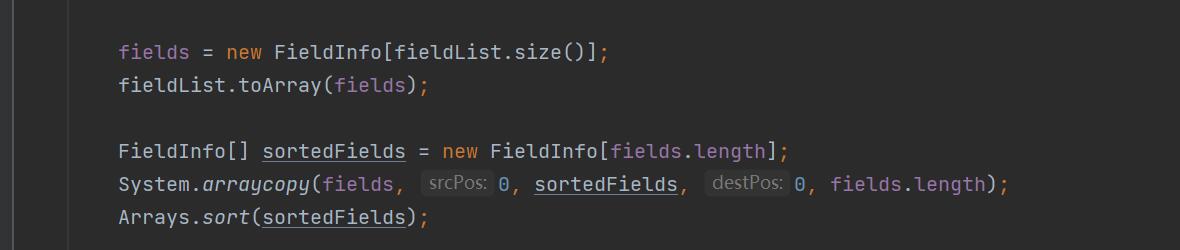
这里需要注意一下这段代码,他会把传入的fieldList进行一个排序,然后赋值给sortedFields
接下来走到这,重新new了一个JavaBeanDeserializer对象,不过和上面的步骤相同,然后返回
No8 parseObject()->deserializer.deserialze()
返回以后最后赋值给了deserializer,也就是No6
我们看到deserializer有一个sortedFieldDesrializers,也就是No7中的sortedFields
接下来直接看到parseField
这个函数主要就是用来调用getXxx或者setXxx,对Xxx进行一些赋值操作
进入此函数,可以看到开头有一个smartMatch
节选一段重要代码1
2
3
4
5
6
7
8
9
10
11
12
13
14public FieldDeserializer smartMatch(String key)
{
if (snakeOrkebab) {
fieldDeserializer = getFieldDeserializer(key2);
if (fieldDeserializer == null) {
for (FieldDeserializer fieldDeser : sortedFieldDeserializers) {
if (fieldDeser.fieldInfo.name.equalsIgnoreCase(key2)) {
fieldDeserializer = fieldDeser;
break;
}
}
}
}
}
key2就是getXxx或者setXxx对应的Xxx
上面的代码就是从sortedFieldDeserializers数组中(No7中的fieldList)寻找是否有可以匹配得到的,匹配得到就返回FieldDeserializer,匹配不到就返回null
如果是null就会执行的下面的代码1
2
3
4
5
6
7
8
9
10
11
12Object deserOrField = extraFieldDeserializers.get(key);
if (deserOrField != null) {
if (deserOrField instanceof FieldDeserializer) {
fieldDeserializer = ((FieldDeserializer) deserOrField);
} else {
Field field = (Field) deserOrField;
field.setAccessible(true);
FieldInfo fieldInfo = new FieldInfo(key, field.getDeclaringClass(), field.getType(), field.getGenericType(), field, 0, 0, 0);
fieldDeserializer = new DefaultFieldDeserializer(parser.getConfig(), clazz, fieldInfo);
extraFieldDeserializers.put(key, fieldDeserializer);
}
}
从extraFieldDeserializers中get相应的field
extraFieldDeserializers是一个HashMap,键是所有的成员变量,值是成员变量对应的field,最后fieldDeserializer就是对相应field进行一次封装
最后用这个封装好的类进行parseField
No9 parseObject()->deserializer.deserialze()->parseField()->fieldDeserializer.parseField()
首先对value进行解析,这里可以看到,如果是byte类型,那么就会对其进行一个base64解码
所以如果要给byte类型进行反序列化,那么就需要先进行一次base64加密
赋值完以后就进入了setValue操作,给反序列化的对象设置值
setValue的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80public void setValue(Object object, Object value) {
if (value == null //
&& fieldInfo.fieldClass.isPrimitive()) {
return;
}
try {
Method method = fieldInfo.method;
if (method != null) {
if (fieldInfo.getOnly) {
if (fieldInfo.fieldClass == AtomicInteger.class) {
AtomicInteger atomic = (AtomicInteger) method.invoke(object);
if (atomic != null) {
atomic.set(((AtomicInteger) value).get());
}
} else if (fieldInfo.fieldClass == AtomicLong.class) {
AtomicLong atomic = (AtomicLong) method.invoke(object);
if (atomic != null) {
atomic.set(((AtomicLong) value).get());
}
} else if (fieldInfo.fieldClass == AtomicBoolean.class) {
AtomicBoolean atomic = (AtomicBoolean) method.invoke(object);
if (atomic != null) {
atomic.set(((AtomicBoolean) value).get());
}
} else if (Map.class.isAssignableFrom(method.getReturnType())) {
Map map = (Map) method.invoke(object);
if (map != null) {
map.putAll((Map) value);
}
} else {
Collection collection = (Collection) method.invoke(object);
if (collection != null) {
collection.addAll((Collection) value);
}
}
} else {
method.invoke(object, value);
}
return;
} else {
final Field field = fieldInfo.field;
if (fieldInfo.getOnly) {
if (fieldInfo.fieldClass == AtomicInteger.class) {
AtomicInteger atomic = (AtomicInteger) field.get(object);
if (atomic != null) {
atomic.set(((AtomicInteger) value).get());
}
} else if (fieldInfo.fieldClass == AtomicLong.class) {
AtomicLong atomic = (AtomicLong) field.get(object);
if (atomic != null) {
atomic.set(((AtomicLong) value).get());
}
} else if (fieldInfo.fieldClass == AtomicBoolean.class) {
AtomicBoolean atomic = (AtomicBoolean) field.get(object);
if (atomic != null) {
atomic.set(((AtomicBoolean) value).get());
}
} else if (Map.class.isAssignableFrom(fieldInfo.fieldClass)) {
Map map = (Map) field.get(object);
if (map != null) {
map.putAll((Map) value);
}
} else {
Collection collection = (Collection) field.get(object);
if (collection != null) {
collection.addAll((Collection) value);
}
}
} else {
if (field != null) {
field.set(object, value);
}
}
}
} catch (Exception e) {
throw new JSONException("set property error, " + fieldInfo.name, e);
}
}
大致的思路就是看之前的fieldInfo中是否有method,在No7中有相关的操作,如果有就会去invoke。
所以如果有相关的getXxx方法或者setXxx想去调用,那在反序列化的时候必须把相关的Xxx变量加到json数据中,这样才会有相应的变量封装到fieldDeserializer(No8步骤),之后才会在setValue的时候去调用对应的getXxx或者setXxx方法
总结
大致思路就是如此,光听文章分析能学到的东西是很有限的,最后还是需要自己动手去调试。
在写这篇文章之前也不知道一些绕过方法,只是分析了一下fastjson的原理,后面看到网上的那些方法,没想到我竟然凑巧把这些绕过payload自己搞出来了,还是有点小高兴。所以说知道原理还是很重要的。
在下一篇就研究一下fastjson的反序列化利用,和一些绕过payload